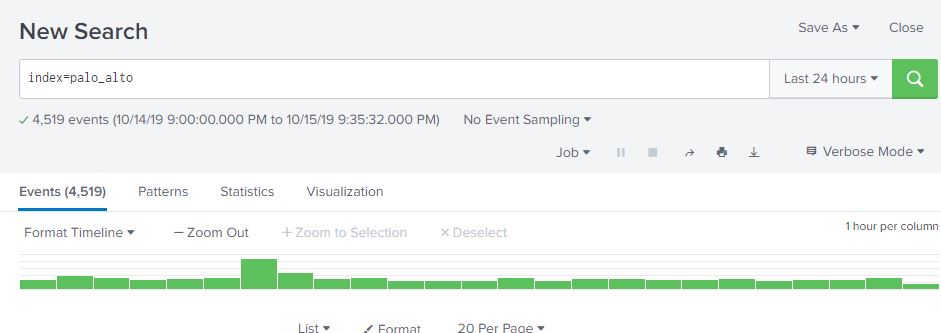
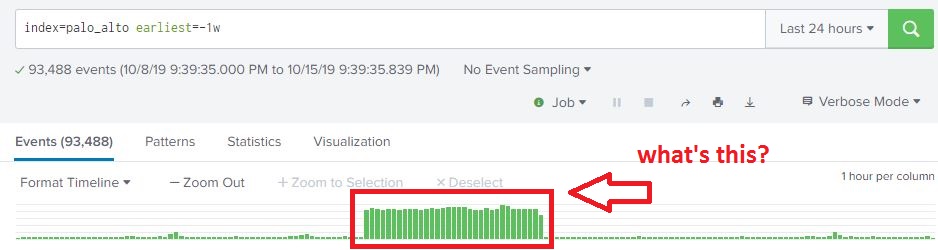
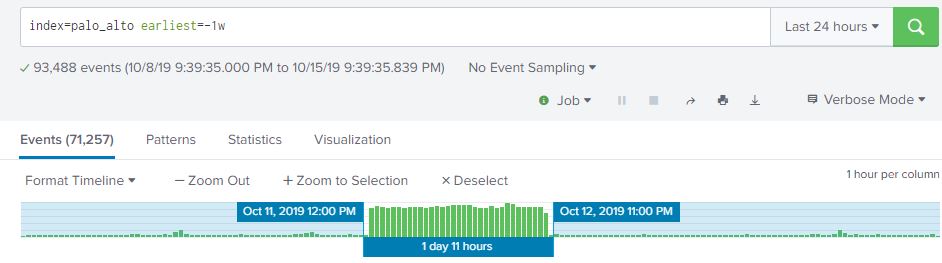
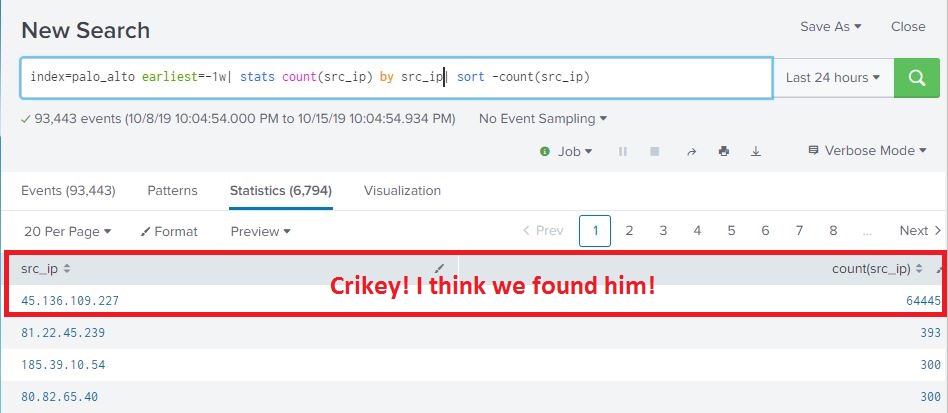
At work, I’m mentoring an computer science intern. One of the tasks I’m working on is to enumerate all of the Windows CIFS/SMB shares with weak permissions and characterize the data contained in them. Sort of a poor man’s DLP. Working with the intern, we have a Bash script written my me that does a masscan looking for ports 135/445 open, and attempts to enumerate shares using a generic account and nmap’s smb-enum module.
Once enumeration is done, the script does some mangling of the output and creates a list of //<ipaddress>/<sharename>, one share per line. A Python script them does an os.walk of the share and recursively grabs all the filenames it can. These ip address, shares, paths, and filenames are then stored in a MySQL database (in 3NF no less!) and can be queries so we can get a rough idea, based on filenames, of what kind of data we are looking at.
A good start, but really lacks contextual data. Of course, this is version .99BETA and we actually got some interesting hits, enough for management to let us continue the work. The number of files we saw were in the millions and would take an extremely long time for a single-threaded Python script running on an old, beat up workstation to process, so we’re moving on up. I figure the MySQL database is OK for right now, but if we start looking at data contents… well, we’re going to need Big Daddy Data. This looks like a job for Elasticsearch!
ES has a plugin called ingest-attachment that will index attachments. This is based on Apache Tika, which is pretty nifty for extracting data from all kinds of file formats. The files must be Base64 encoded when being uploaded to Elastic. First, stop Elastic:
service elasticsearch stopNext install the ingest-attachment plugin:
/usr/share/elasticsearch/bin/elasticsearch-plugin install ingest-attachmentRestart Elasticsearch
systemctl start elasticsearchNow we need a to create a pipeline in Elastic so that the data coming in is send to ingest-attachment. This definition will create a pipeline of an arbitrary name, which for this example we’ll call ‘mcboatface’, and a field called ‘data’ in which the base64 string will be stored.
curl -X PUT -H "Content-Type: application/json" "localhost:9200/_ingest/pipeline/mcboatface" -d'
{
"description":"Extract attachment information",
"processors":[
{
"attachment":{
"field":"data",
"indexed_chars":-1
}
}
]
}'Now that the pipeline is created, we need a small sample file file to play with
[root@localhost tmp]# echo "Lorum ipsum blah blah blah" > test.txt
[root@localhost tmp]# base64 test.txt
TG9ydW0gaXBzdW0gYmxhaCBibGFoIGJsYWgK
Now we upload the Base64 string into an index called “test”, invoking the mcboatface pipeline so the data gets decoded and indexed. The string gets PUT into the data field of the index, we also must supply a ID# for the attachment, which will be 1.
curl -X PUT -H "Content-Type: application/json" "localhost:9200/test/_doc/1?pipeline=mcboatface" -d'
{
"data":"TG9ydW0gaXBzdW0gYmxhaCBibGFoIGJsYWgK"
}'Now we can write a query for the document. The trick here is that we are querying against the “attachment.content” field, which may not be obvious for beginning Elasticsearchers.
curl -X GET -H "Content-Type: application/json" "localhost:9200/test/_search?pretty" -d'
{ "query":{
"match":{"attachment.content":"blah"}
}
}'
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.45207188,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.45207188,
"_source" : {
"data" : "TG9ydW0gaXBzdW0gYmxhaCBibGFoIGJsYWgK",
"attachment" : {
"content_type" : "text/plain; charset=ISO-8859-1",
"language" : "is",
"content" : "Lorum ipsum blah blah blah",
"content_length" : 28
}
}
}
]
}
}So that’s all pretty cool and stuff, but what about for bigger documents? I ran into two problems really fast- base64 by default will put in line breaks at 76 columns, and \n is not a legal base64 char. Trust me on this. Second is that Curl doesn’t like really long strings to be passed as an argument and will complain. So, goven these two things, first b64 encode the PDF without line breaks:
base64 -w 0 Google_searching.pdf > test.jsonNow you’ll have to do a little preformatting by editing the test.json file and making it look like JSON data:
{"data":"JVBERi0xLjUNCiW1tbW1DQox...
<lots of base64 data here>
...o2ODI0MTANCiUlRU9G"}
Now we can use Curl’s “-d @<filename>” option to tell it to POST the data in the file. Since it’s preforrmated JSON data, it should just slide right in
curl -X PUT -H "Content-Type: application/json" "localhost:9200/test/_doc/2?pipeline=attachment&pretty" -d @test.json
{
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"_version" : 1,
"result" : "created",
"_shards" : {
"total" : 2,
"successful" : 1,
"failed" : 0
},
"_seq_no" : 1,
"_primary_term" : 1
}
And is now searchable
curl -H "Content-Type: application/json" "localhost:9200/test/_search?pretty" -d'
{
"query":{
"match":{"attachment.content":"Firefox"}
}
}'
{
"took" : 1219,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.5022252,
"hits" : [
{
"_index" : "test",
"_type" : "_doc",
"_id" : "2",
"_score" : 0.5022252,
"_source" : {
"data" : "JVBERi0xLjU
<lots of output>
"attachment" : {
"date" : "2015-11-03T02:06:29Z",
"content_type" : "application/pdf",
"author" : "Kate",
"language" : "en",
"content" : "Searching Google: tips & tricks \n\n \n\n \n\nhttp://www.google.co.nz/ \n\nSearching Google \nThis guide covers selected tips and tricks to refine your search technique – for more \n\ninformation, consult Google’s various help screens. \n\nPlease note: \n\n The tips and tricks described on this guide are subject to change. \n\n Google can personalise search results. Your search results may be different from \n\nsomeone else’s and may vary according to the computer you are using. \n\n This guide is based on the Chrome browser - FirefoxAnd that’s basically it!